Lots of Null After Read Xbee Until
Earlier you start whatever information project, y'all need to take a stride back and look at the dataset before doing annihilation with it. Exploratory Information Analysis (EDA) is just as important every bit whatever part of data analysis considering real datasets are really messy, and lots of things can go incorrect if you don't know your data. The Pandas library is equipped with several handy functions for this very purpose, and value_counts is 1 of them. Pandas value_counts returns an object containing counts of unique values in a pandas dataframe in sorted order. Nonetheless, most users tend to overlook that this function can be used non only with the default parameters. Then in this article, I'll show yous how to get more value from the Pandas value_counts by altering the default parameters and a few additional tricks that will salvage y'all fourth dimension.
What is value_counts() function?
The value_counts() function is used to go a Series containing counts of unique values. The resulting object will exist in descending order so that the first element is the most frequently-occurring element. Excludes NA values by default.
Syntax
df['your_column'].value_counts() - this volition return the count of unique occurences in the specified column.
It is important to note that value_counts only works on pandas series, non Pandas dataframes. As a result, we only include one bracket df['your_column'] and non two brackets df[['your_column']].
Parameters
- normalize (bool, default Faux) - If Truthful so the object returned will comprise the relative frequencies of the unique values.
- sort (bool, default True) - Sort by frequencies.
- ascending (bool, default Simulated) - Sort in ascending society.
- bins (int, optional) - Rather than count values, group them into one-half-open bins, a convenience for
pd.cutting, only works with numeric data. - dropna (bool, default True) -Don't include counts of NaN.
Loading a dataset for live demo
Permit's run into the basic usage of this method using a dataset. I'll exist using the Coursera Grade Dataset from Kaggle for the alive demo. I take also published an accompanying notebook on git, in case you desire to get my lawmaking.
Let'southward start by importing the required libraries and the dataset. This is a fundamental pace in every data assay procedure. And so review the dataset in Jupyter notebooks.
# import package import pandas as pd # Loading the dataset df = pd.read_csv('coursea_data.csv') #quick await well-nigh the information of the csv df.caput(10) 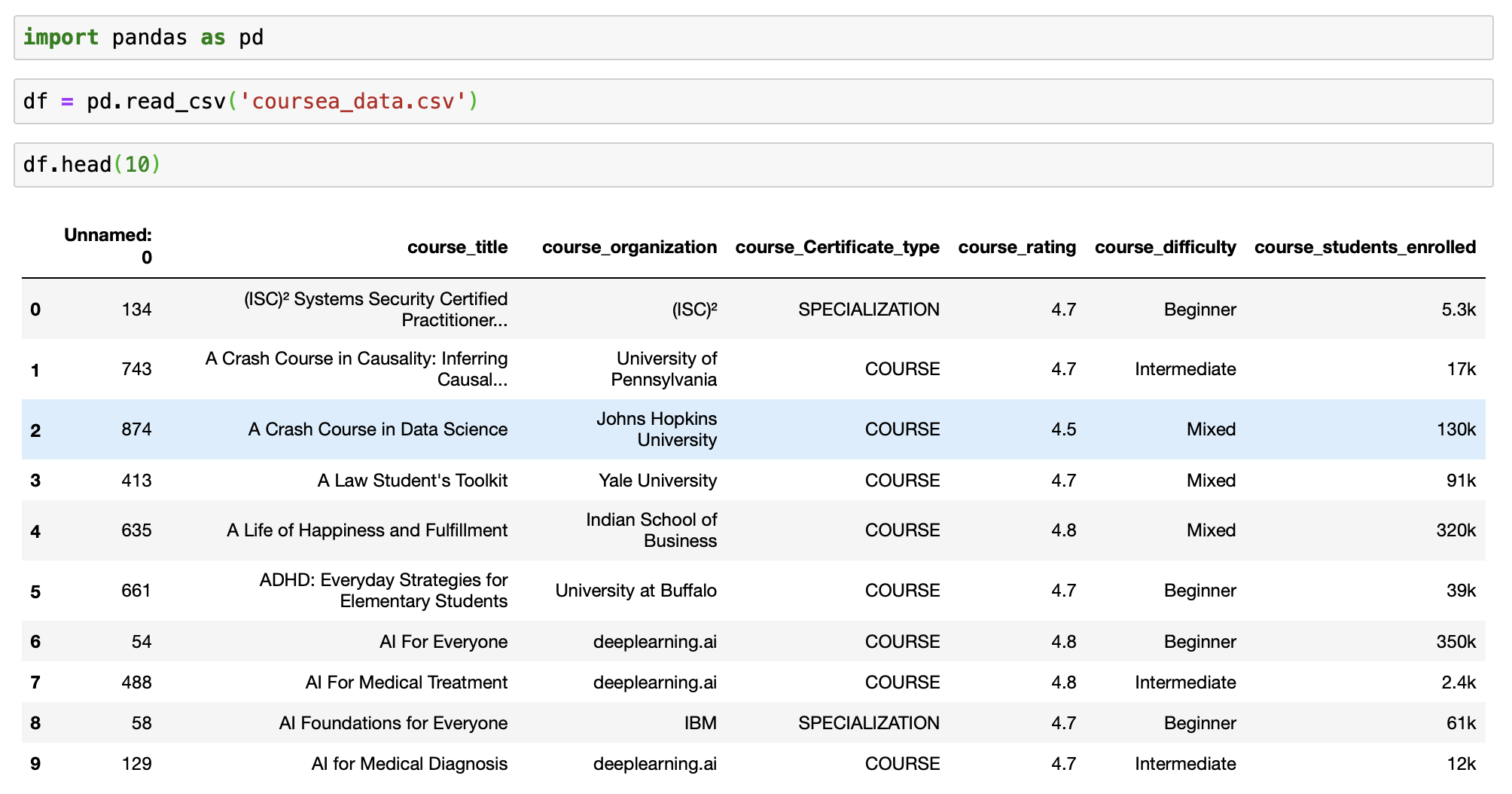
# check how many records are in the dataset # and if we have any NA df.info() 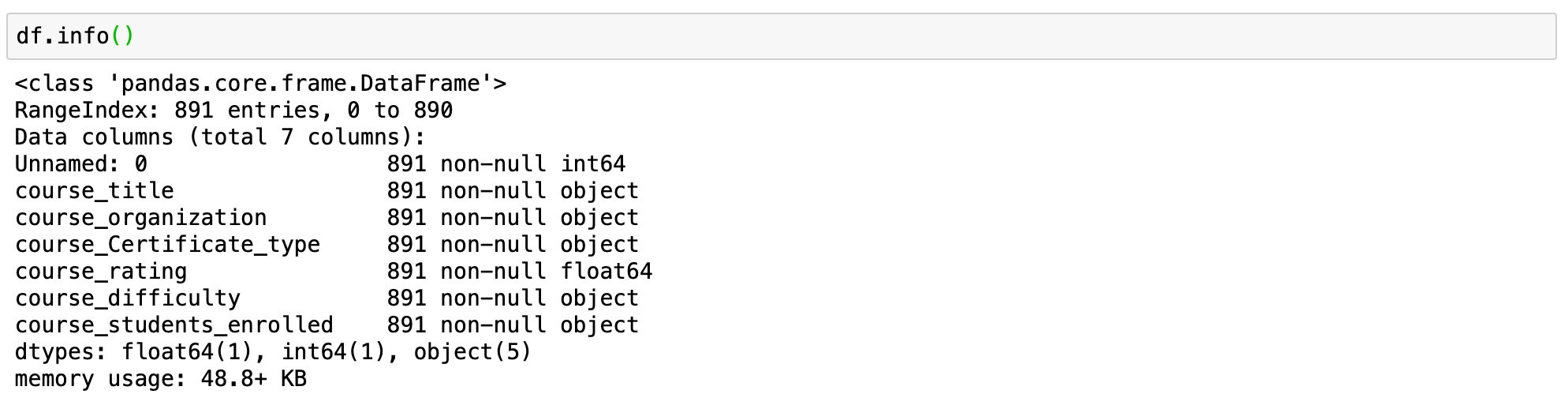
This tells us that we accept 891 records in our dataset and that nosotros don't take any NA values.
1. ) value_counts() with default parameters
Now we are ready to use value_counts role. Let begin with the basic application of the part.
Syntax - df['your_column'].value_counts()
We will get counts for the column course_difficulty from our dataframe.
# count of all unique values for the column course_difficulty df['course_difficulty'].value_counts() 
The value_counts function returns the count of all unique values in the given index in descending guild without any null values. We tin quickly run into that the maximum courses have Beginner difficulty, followed by Intermediate and Mixed, and so Advanced.
Now that we understand the basic use of the function, it is time to figure out what parameters do.
2.) value_counts() in ascending order
The series returned by value_counts() is in descending order past default. Nosotros can contrary the case past setting the ascending parameter to True.
Syntax - df['your_column'].value_counts(ascending=True)
# count of all unique values for the column course_difficulty # in ascending order df['course_difficulty'].value_counts(ascending=True) 
three.) value_counts() sorted alphabetically
In some cases it is necessary to display your value_counts in an alphabetical lodge. This can be done easily by adding sort alphabetize sort_index(ascending=Truthful) after your value_counts().
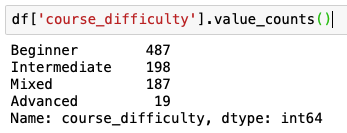
Default value_counts() for column "course_difficulty" sorts values past counts:
Value_counts() with sort_index(ascending=True) sorts past index (column that you lot are running value_counts() on:
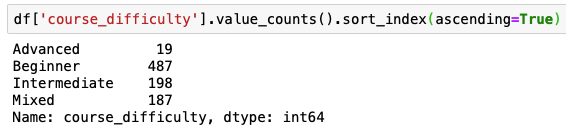
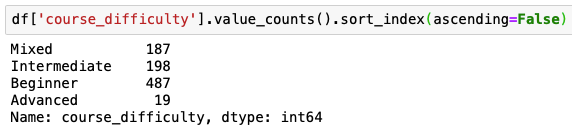
If you want to listing value_counts() in reverse alphabetical lodge y'all will need to change ascending to False sort_index(ascending=Imitation)
iv.) Pandas value_counts(): sort by value, then alphabetically
Lets use for this example a slightly diffrent dataframe.
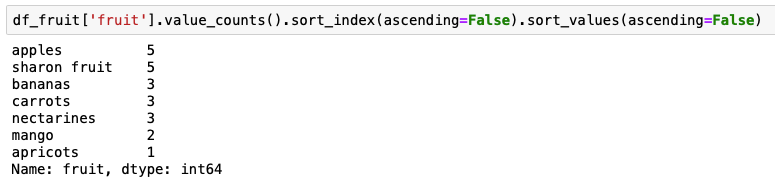
df_fruit = pd.DataFrame({ 'fruit': ['sharon fruit']*5 + ['apples']*5 + ['bananas']*3 + ['nectarines']*3 + ['carrots']*3 + ['apricots'] + ['mango']*2 }) Here nosotros want to get output sorted offset by the value counts, and then alphabetically past the name of the fruit. This can be done by combining value_counts() with sort_index(ascending=False) and sort_values(ascending=False).
5.) value_counts() persentage counts or relative frequencies of the unique values
Sometimes, getting a percentage count is better than the normal count. Past setting normalize=Truthful, the object returned will incorporate the relative frequencies of the unique values. The normalize parameter is set to Imitation by default.
Syntax - df['your_column'].value_counts(normalize=True)
# value_counts percentage view df['course_difficulty'].value_counts(normalize=True) 
6.) value_counts() to bin continuous data into discrete intervals
This is i great hack that is commonly under-utilised. The value_counts() can be used to bin continuous data into discrete intervals with the help of the bin parameter. This option works only with numerical data. It is similar to the pd.cut part. Permit's encounter how it works using the course_rating column. Allow's grouping the counts for the column into iv bins.
Syntax - df['your_column'].value_counts(bin = number of bins)
# applying value_counts with default parameters df['course_rating'].value_counts() # applying value_counts on a numerical cavalcade # with the bin parameter df['course_rating'].value_counts(bins=iv) 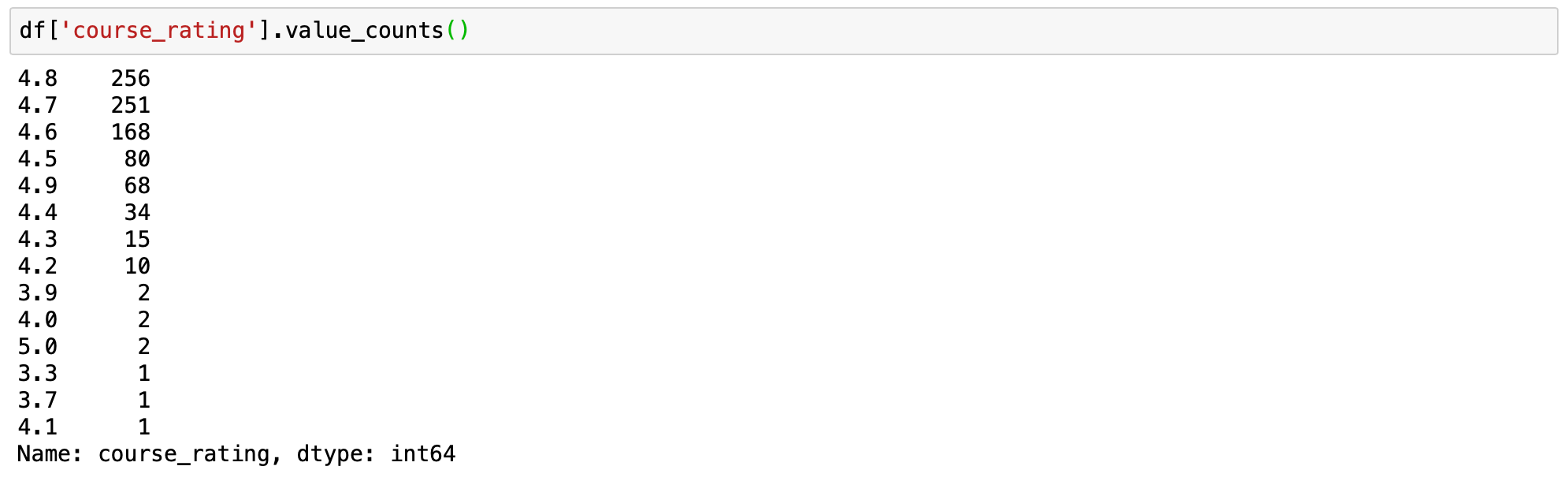

Binning makes it easy to empathize the idea being conveyed. We tin can hands see that nearly of the people out of the total population rated courses to a higher place 4.v. With simply a few outliers where the rating is below 4.15 (only 7 rated courses lower than 4.15).
7.) value_counts() displaying the NaN values
By default, the count of null values is excluded from the result. But, the same can exist displayed easily by setting the dropna parameter to False. Since our dataset does not have any null values setting dropna parameter would not make a difference. But this tin can be of use on some other dataset that has null values, so keep this in heed.
Syntax - df['your_column'].value_counts(dropna=False)
8.) value_counts() as dataframe
Every bit mentioned at the get-go of the article, value_counts returns series, non a dataframe. If yous want to accept your counts as a dataframe you can practise information technology using part .to_frame() after the .value_counts().
We can catechumen the serial to a dataframe every bit follows:
Syntax - df['your_column'].value_counts().to_frame()
# applying value_counts with default parameters df['course_difficulty'].value_counts() # value_counts every bit dataframe df['course_difficulty'].value_counts().to_frame() 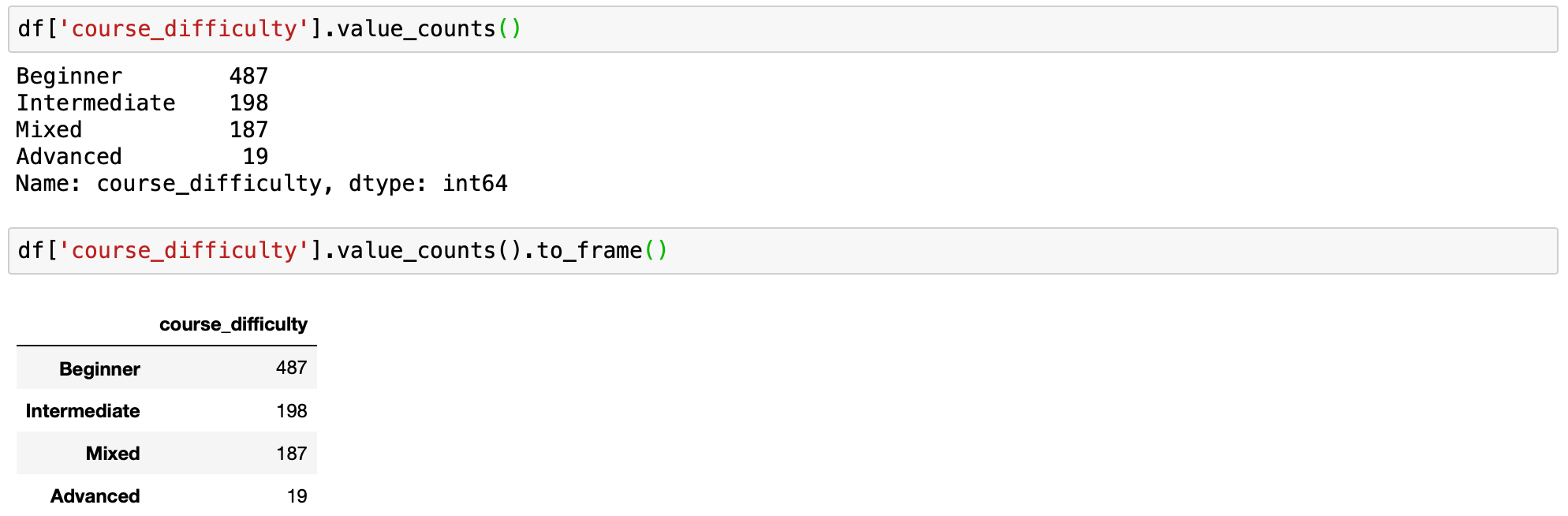
If you need to proper noun index cavalcade and rename a cavalcade, with counts in the dataframe you can convert to dataframe in a slightly unlike way.
value_counts = df['course_difficulty'].value_counts() # converting to df and assigning new names to the columns df_value_counts = pd.DataFrame(value_counts) df_value_counts = df_value_counts.reset_index() df_value_counts.columns = ['unique_values', 'counts for course_difficulty'] # change cavalcade names df_value_counts 9.) Group by and value_counts
This is one of my favourite uses of the value_counts() function and an underutilized one besides. Groupby is a very powerful pandas method. You can group by one cavalcade and count the values of another column per this cavalcade value using value_counts.
Syntax - df.groupby('your_column_1')['your_column_2'].value_counts()
Using groupby and value_counts we can count the number of certificate types for each blazon of class difficulty.
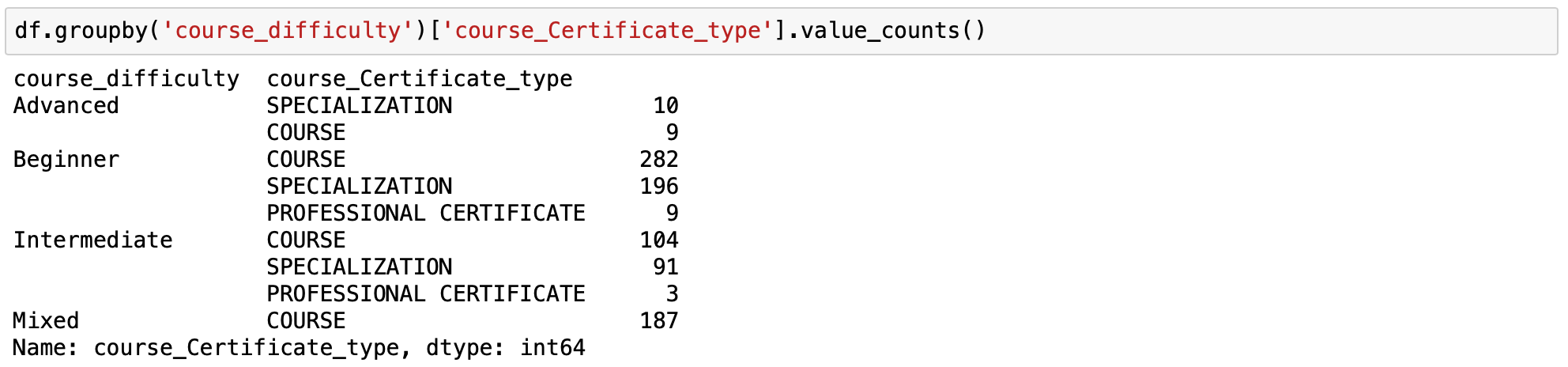
This is a multi-alphabetize, a valuable play a joke on in pandas dataframe which allows u.s. to have a few levels of index hierarchy in our dataframe. In this case, the grade difficulty is the level 0 of the index and the certificate type is on level 1.
10. Pandas Value Counts With a Constraint
When working with a dataset, you may need to return the number of occurrences past your index column using value_counts() that are also limited by a constraint.
Syntax - df['your_column'].value_counts().loc[lambda x : x>ane]
The in a higher place quick one-liner volition filter out counts for unique data and run into merely data where the value in the specified column is greater than 1.
Let's demonstrate this by limiting course rating to be greater than 4.
# prints standart value_counts for the cavalcade df['course_rating'].value_counts() # prints filtered value_counts for the cavalcade df['course_rating'].value_counts().loc[lambda x : x>4] 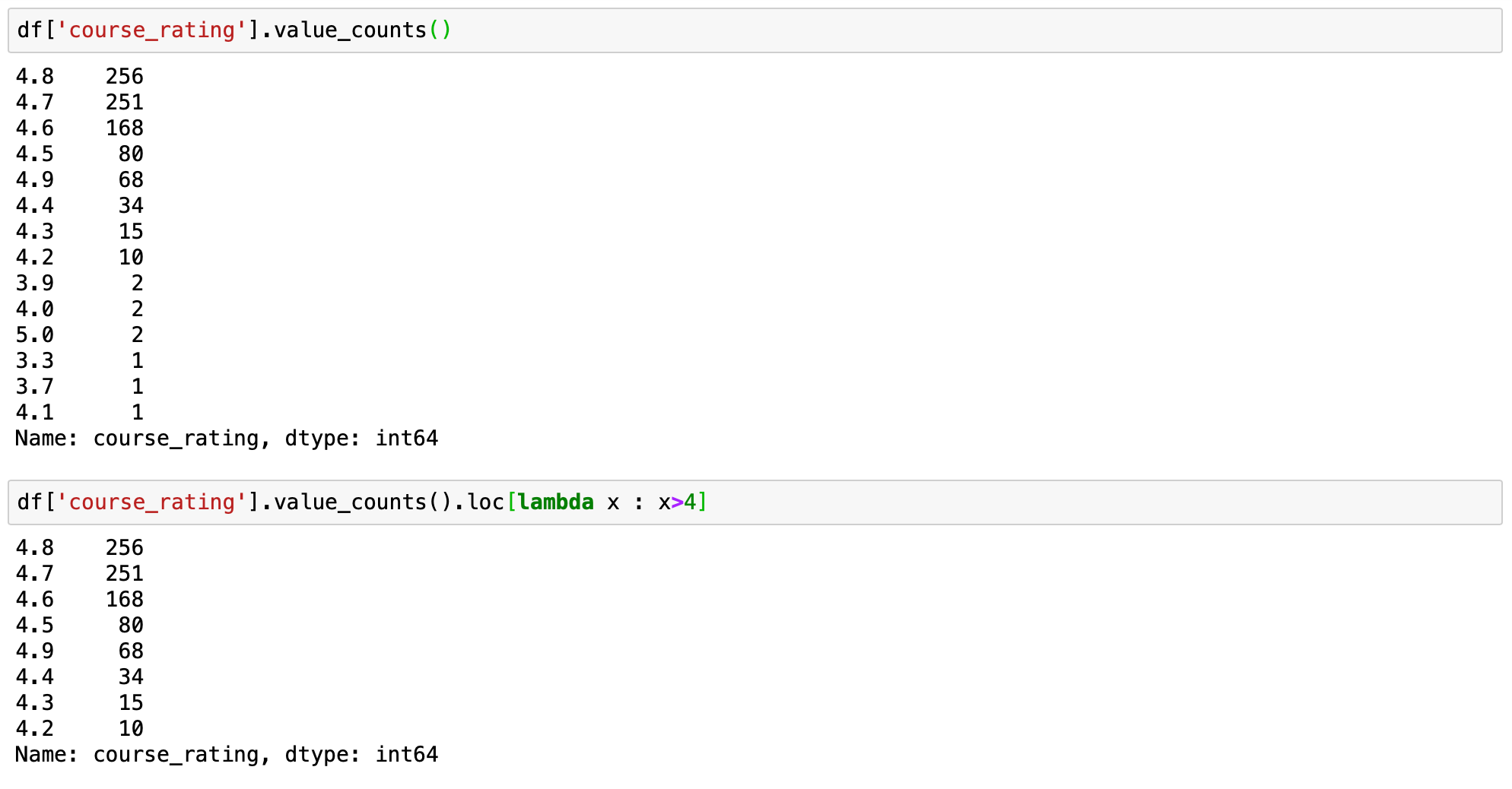
Hence, we tin see that value counts is a handy tool, and we can practice some interesting analysis with this single line of code.
Lots of Null After Read Xbee Until
Source: https://re-thought.com/pandas-value_counts/
0 Response to "Lots of Null After Read Xbee Until"
Post a Comment